[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Driving New Integrations with Confluent and ksqlDB at ACERTUS
Get started with Confluent, for free
Watch demo: Streaming data pipelines to Snowflake
When companies need help with their vehicle fleets—including transport, storage, or renewing expired registrations—they don’t want to have to deal with multiple vehicle logistics providers. For these companies, ACERTUS provides a one-stop shop for solutions ranging from title and registration, to care and maintenance, to car hauling and drive-away services in all 50 U.S. states as well as Puerto Rico and Canada.
It was through a series of acquisitions over the last three to four years that ACERTUS assembled its comprehensive array of vehicle lifecycle solutions. Until fairly recently, however, the core data systems of those companies had not been well integrated. As a result, our teams relied heavily on manual processes involving email, phone calls, spreadsheets, and even Zendesk tickets to move data between systems when new orders were created or updated. The manual workflows were labor-intensive and prone to errors and delays as order information was manually typed or copied from system to system.
When one of ACERTUS’ top five largest customers requested a new integrated end-to-end solution that would incorporate many of our services—picking up vehicles; washing, fueling, and servicing them as needed; and then delivering them to their destinations—it was clear that we would need better integration among our core systems. The challenge of architecting and implementing a solution fell to me and my team. The solution we built with Confluent and ksqlDB enabled us to lower costs, increase automation, eliminate errors, and open new business opportunities that are already generating more than $10 million in revenue in the first year. Now when an order comes in, the order data flows over an Apache Kafka® topic to the downstream systems that need it in near real time, with no manual intervention and none of the errors that come with it.
Our objective
Ultimately, we had three goals:
- Automate the backend process to deliver cars to consumers faster and reduce reliance on manual operations
- Create a single view of customers and provide a real-time digital experience for tracking the status of their cars
- Deliver new features and capabilities quickly, such as real-time push notifications for vehicle pickup, to improve customer engagement
Because each of our three business units had been operating as its own monolith, we needed to break down each of those monoliths into microservices. Then we could easily share customer, vehicle, and transit data to the different lines of businesses across the company. The idea was to assign each vehicle a unique ID, ingest metadata about that vehicle that matters to buyers and sellers (VIN, mileage, defects, and current location), and disseminate that information to downstream consumers for pickup location, title, registration, and immediate sale price.
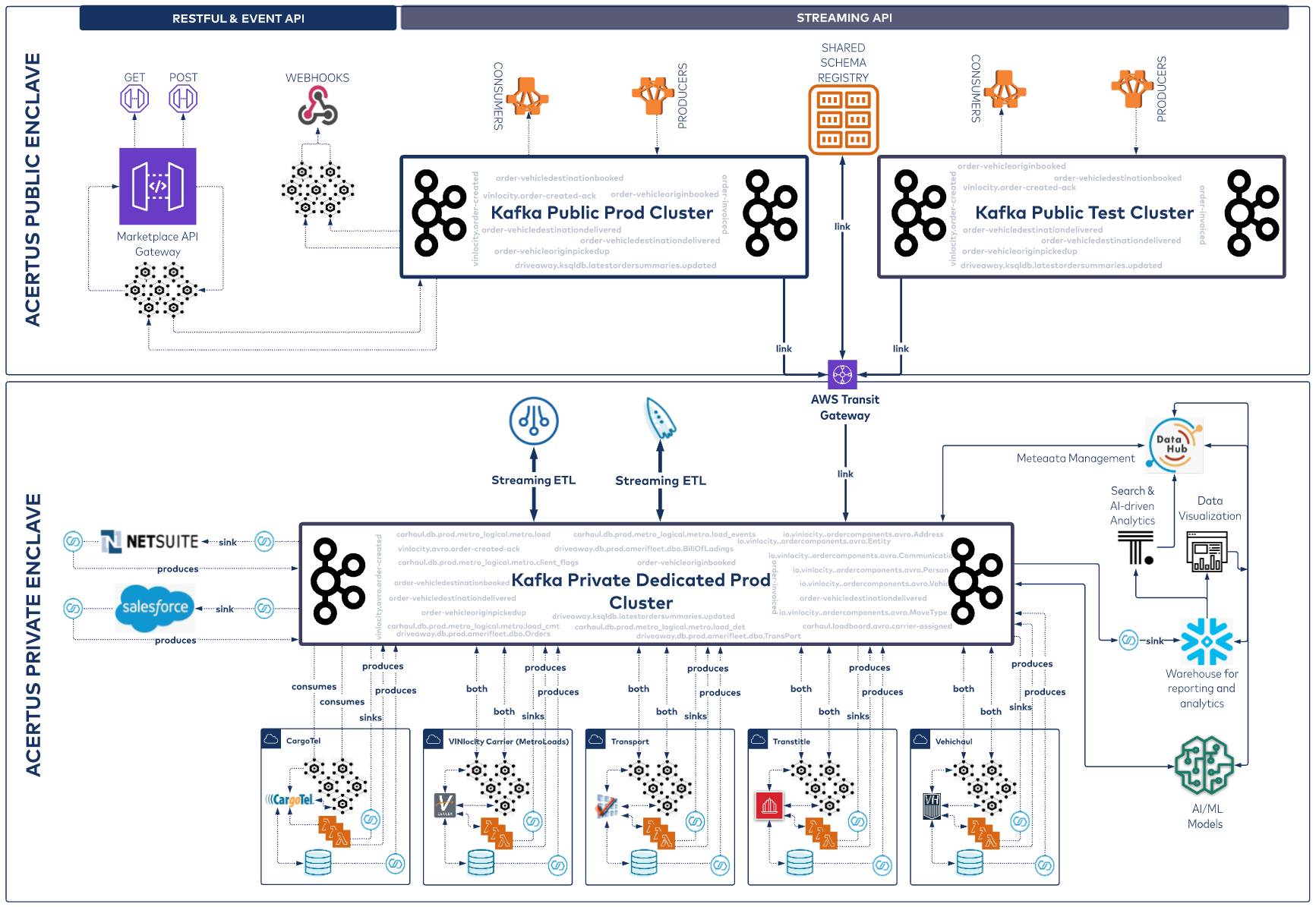
A look at the architecture
At a high level, the architecture we established is partitioned into two enclaves: one public and one private. Customers access the public enclave, where they can initiate the order process via a RESTful API that connects to a public Kafka cluster through a microservice. Alternatively, customers can use our Streaming API, which provides direct access to the public Kafka cluster.
The public cluster is connected via Cluster Linking to our internal Kafka cluster within the ACERTUS private enclave. The private cluster is part of a Confluent environment that serves as a central nervous system connecting core ACERTUS systems, including transportation management, title and registration, and car haul systems. We use AWS Lambda and Confluent connectors to power the integrations with these systems; and we also use the Snowflake Sink Connector for Confluent Cloud to link with our Snowflake data warehouse for reporting and analytics. The producers and consumers in both the public and private enclaves talk to a shared Schema Registry instance, enabling centralized schema management and evolution.
ksqlDB plays a transformative role
Within our architecture, stream processing with ksqlDB plays a vital role in enriching and transforming our raw data streams.
One of our first goals was automating the backend process, so customers could have faster deliveries. Previously, our cross-functional teams would rely heavily on manual operations—multiple phone calls, spreadsheets, and hundreds of Zendesk tickets. By using ksqlDB, we were able to easily merge real-time data streams coming in from each line of business and create a materialized view that fires off an event as soon as new order data is available. That event is consumed by a microservice linked to our transportation management system. The entire process is simple, instantaneous, and error-free. By merging the data streams, teams no longer needed to manually send customer data back and forth. This boosted employee productivity and delivered a more seamless customer experience.
Next, we wanted to develop a 360-degree customer view and provide new features and functionalities to enhance the real-time interactions between us and our customers. Our previous functionalities prevented ACERTUS from obtaining an integrated real-time view of our customer because we were using batch-oriented, ETL processes. So after we started using Kafka to help store our raw, unstructured data, we thought, why not use ksqlDB to change the way we run our extract, transform, and load (ETL) pipelines. We had been using a legacy tool for ETL processing, but we moved away from that batch-oriented process to streaming data pipelines with ksqlDB. Now all customer interactions are sent as real-time events into Confluent and dynamically transformed with the help of ksqlDB. With Confluent, we’ve adopted event-centric thinking and simplified the processing of real-time event streams, enabling us to reveal immediate insights about our customers that would not have been otherwise possible from raw interaction data alone.
One of the big advantages of transitioning from a specialized ETL tool to ksqlDB stems from the fact that our continuous integration/continuous delivery (CI/CD) pipeline is critical to what we do. With ksqlDB migrations, we can integrate our ksqlDB development cleanly into our CI/CD pipelines as we build and evolve stream processing applications. Instead of doing all of our work in a single environment, we have set up GitHub actions and a test environment, where we can run tests as part of our CI/CD pipeline, before any updates are pushed to the production environment. This means faster time to market and higher-quality features and functionalities.
Next steps
As we shift our thinking as an organization from a synchronous, API-first mindset to one that is more asynchronous and oriented around data streaming, we are seeing fresh opportunities for onboarding new online retail car dealers and other customers who will benefit from a combination of the services that ACERTUS offers. We’re rapidly growing that part of our business, and we simply would not have been able to do it without the architecture and integrations we put in place with Confluent and ksqlDB.
If you’d like to get started with Confluent Cloud, sign up for a free trial and use the promo code CL60BLOG for an extra $60 of free Confluent Cloud usage.*
Get started with Confluent, for free
Watch demo: Streaming data pipelines to Snowflake
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Confluent’s Customer Zero: Building a Real-Time Alerting System With Confluent Cloud and Slack
Turning events into outcomes at scale is not easy! It starts with knowing what events are actually meaningful to your business or customer’s journey and capturing them. At Confluent, we have a good sense of what these critical events or moments are.


How To Automatically Detect PII for Real-Time Cyber Defense
Our new PII Detection solution enables you to securely utilize your unstructured text by enabling entity-level control. Combined with our suite of data governance tools, you can execute a powerful real-time cyber defense strategy.