[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Monitoring Data Replication in Multi-Datacenter Apache Kafka Deployments
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Enterprises run modern data systems and services across multiple cloud providers, private clouds and on-prem multi-datacenter deployments. Instead of having many point-to-point connections between sites, the Confluent Platform provides an integrated event streaming architecture with frictionless data replication between sites.
Applications can publish streams of data to a self-hosted on-prem cluster, replicate them to another on-prem cluster or to different cloud providers, load them into data systems in the cloud and trigger cloud-native applications from those events. In this way, the data stays in sync in near real time between core business applications, regardless of where they are located.
Previously in 3 Ways to Prepare for Disaster Recovery in Multi-Datacenter Apache Kafka Deployments, we provided resources for multi-datacenter designs, centralized schema management, prevention of cyclic repetition of messages, and automatic consumer offset translation to automatically resume applications. The key to the solution is Confluent Replicator, which enables frictionless data replication between sites. I recommend you familiarize yourself with that blog post and the accompanying white paper before proceeding, because this blog post builds on those core concepts.
Once you have deployed a multi-datacenter solution with Confluent Replicator, you can monitor Replicator to ensure that your core applications are meeting SLAs and addressing business needs:
- Is the destination datacenter receiving copies of all data from the origin datacenter?
- Is replication running optimally or do operators need to scale up the number of Replicator tasks?
- How far behind is data replication? (Useful to know in case of a disaster event)
The Confluent Platform allows you to answer these questions, as it provides a resilient, fault-tolerant and flexible management and monitoring solution. First and foremost, Confluent Control Center can manage multi-datacenter Apache Kafka® deployments, whether on prem or in the cloud. Operators can manage those clusters, view topic data and schemas and run ksqlDB queries against data streams.
Control Center also provides valuable insights into how client applications are performing (Kafka clients include any application that uses the Apache Kafka client API to connect to Kafka brokers, such as custom client code or any service that has embedded producers or consumers. This could be Replicator, Kafka Connect, ksqlDB or a Kafka Streams application). It’s not just a data swamp of hundreds of metrics—it is information you can act on.
For example, when Confluent Monitoring Interceptors are configured on Kafka clients, they write metadata to a Kafka topic called _confluent-monitoring. Control Center processes that topic so you can ensure that client applications are receiving all the latest Kafka data and provides statistics on throughput and latency performance. Additionally, Control Center provides consumer lag performance metrics to see how many messages behind the consumer client application is from the end of the log.
Not only can Control Center manage multiple Kafka deployments, it can also manage data replication between them. From within Control Center, users can set up data replication by deploying Replicator to a Kafka Connect cluster. You can run multiple Replicator instances with different configurations. For example, one instance could copy a Kafka topic and rename it in the destination cluster, while another instance can copy a Kafka topic without renaming it.
You can then monitor throughput and latency of all the Replicator instances, as well performance of Replicator’s embedded consumer group on a per-consumer-group basis or per-topic basis.
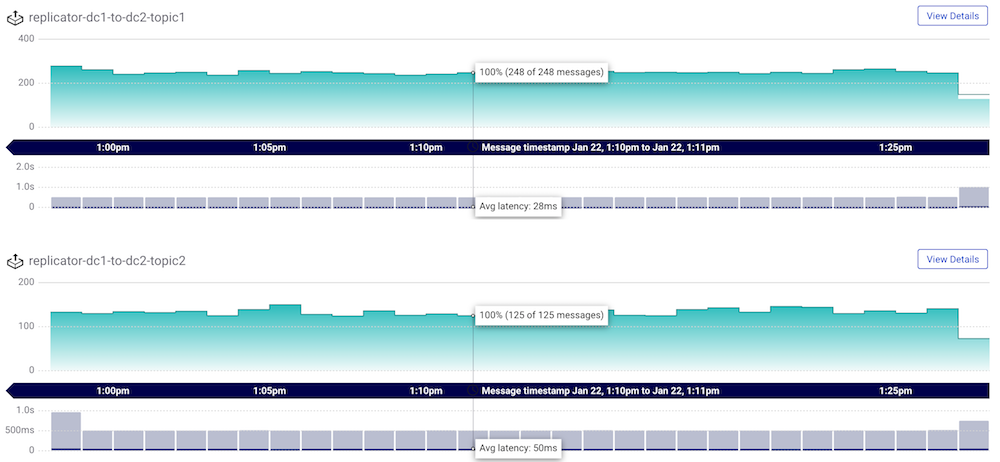
You can also monitor Replicator’s consumer lag to see how many messages behind it is from the latest offset in the log in the origin datacenter, i.e., how in-sync the data is between clusters. Replicator has an embedded consumer that reads data from the origin cluster, and it commits its offsets only after the Connect worker’s producer has committed the data to the destination cluster (configure the frequency of commits with the parameter offset.flush.interval.ms).
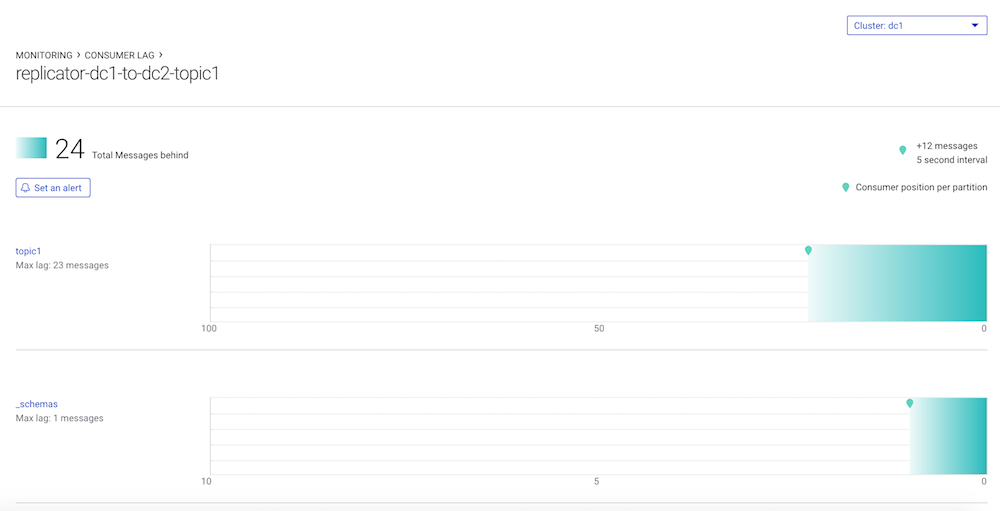
Do not confuse consumer lag with an MBean attribute called records-lag, associated with Replicator’s embedded consumer. That attribute reflects whether Replicator’s embedded consumer can keep up with the original data production rate, but it does not take into account the replication lag that occurs when producing the messages to the destination cluster.
Try it out yourself
Learn more by running our multi-datacenter example in GitHub. In one command, this demo environment brings up an active-active multi-datacenter environment with Confluent Replicator copying data bidirectionally. (Disclaimer: This is just for testing—do not take this Docker setup into production!)
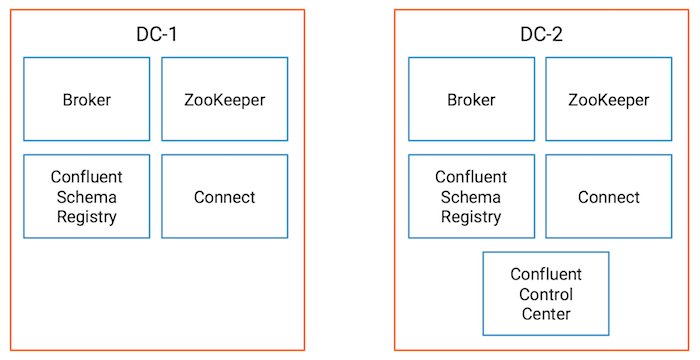
It includes a playbook that walks through several scenarios showing you how to monitor Replicator with Control Center. For testing, you can adapt the configurations to be more representative of your deployment and run your client applications against it. The provided sample Java client application lets you see how data consumption can resume in the new datacenter based on where it left off in the original datacenter.
The demo also shows you how to derive which producers are writing to which topics, and which consumers are reading from which topics, which is especially useful in a more complex multi-datacenter Kafka environment. Control Center uses the interceptor metadata in the _confluent-monitoring topic to check whether all messages are delivered and to provide statistics on throughput and latency performance, but you can also read from that same Kafka topic to derive the mapping of topics to clients. Here is a sample output from the demo:
_schemas
producers
connect-worker-producer-dc2
consumers
replicator-dc1-to-dc2-topic1
topic1 producers connect-worker-producer-dc1 connect-worker-producer-dc2 datagen-dc1-topic1 datagen-dc2-topic1 consumers java-consumer-topic1 replicator-dc1-to-dc2-topic1 replicator-dc2-to-dc1-topic1
topic2 producers datagen-dc1-topic2 consumers replicator-dc1-to-dc2-topic2
topic2.replica producers connect-worker-producer-dc2
In summary, if an enterprise has a mission-critical, multi-datacenter Apache Kafka deployment, it’s important to ensure that data is replicated and stays in sync in near real time between core business applications. Confluent Control Center is great for managing and monitoring data replication in your multi-datacenter deployment.
If you’d like to know more, you can download the Confluent Platform to get started with Control Center and the leading distribution of Apache Kafka.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...