Introducing Connector Private Networking: Join The Upcoming Webinar!
Monitoring Apache Kafka with Confluent Control Center Video Tutorials
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Mission critical applications built on Kafka need a robust and Kafka-specific monitoring solution that is performant, scalable, durable, highly available, and secure. Confluent Control Center helps monitor your Kafka deployments and provides assurances that your services are behaving properly and meeting SLAs. Control Center was designed for Kafka, by the creators of Kafka, from Day Zero. It provides the most important information to act on so you can address important business-level questions:
- Are my brokers up?
- Are applications receiving all data?
- Are they up to date with the latest events?
- Why are the applications running slowly?
- Do we need to scale out?
You may think Kafka is running fine, but how do you prove it?
Control Center can monitor your Kafka cluster and applications with important monitoring features like System health, End-to-end stream monitoring, and Alerting.
Watch the introductory Confluent Control Center video Monitoring Kafka like a Pro (3:30).
If you are in the early phase of your exploration of Confluent Control Center, you can learn more about what it can do by watching the Confluent Control Center Overview video series:
- Intro | Monitoring Kafka in Confluent Control Center
- Cluster Health | Monitoring Kafka in Confluent Control Center
- End-to-End Message Delivery | Monitoring Kafka in Confluent Control Center
- Optimizing Performance | Monitoring Kafka in Confluent Control Center
- Real-world Scenario | Monitoring Kafka in Confluent Control Center
If you are ready to get hands on, check out our Confluent Platform Demo GitHub repo. Following the realistic scenario in this repo, which takes just a few seconds to spin up, you will use Control Center to monitor a Kafka cluster and then walk through a playbook of various operational events. The use case is as follows:
A streaming ETL pipeline built around live edits to real Wikipedia pages. The Wikimedia Foundation has IRC channels that publish edits happening to real wiki pages in real time. Using Kafka Connect, a Kafka source connector kafka-connect-irc streams raw messages from these IRC channels, and a custom Kafka Connect transform kafka-connect-transform-wikiedit transforms these messages and then the messages are written to Kafka. This demo uses KSQL for data enrichment, or you can optionally develop and run your own Kafka Streams application. Then a Kafka sink connector kafka-connect-elasticsearch streams the data out of Kafka, and the data is materialized into Elasticsearch for analysis by Kibana.
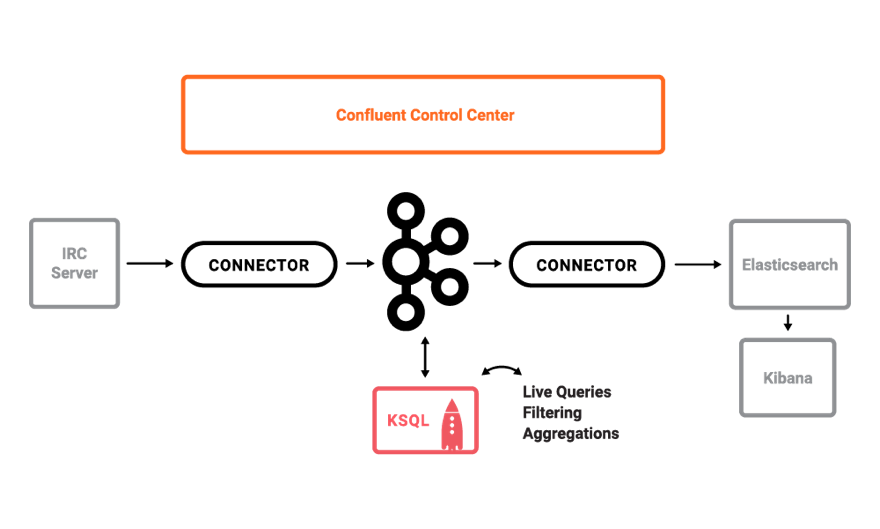
The cp-demo repo comes with a playbook for operational events and corresponding video tutorials of useful scenarios to run through with Control Center:
You can also download the Confluent Platform and bring up your own cluster and Confluent Control Center locally with the quickstart.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...