Introducing Connector Private Networking: Join The Upcoming Webinar!
Journey to Event Driven – Part 3: The Affinity Between Events, Streams and Serverless
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
With serverless being all the rage, it brings with it a tidal change of innovation. Given that it is at a relatively early stage, developers are still trying to grok the best approach for each cloud vendor and often face the following question: Should I go cloud native with AWS Lambda, GCP functions, etc., or invest in a vendor-agnostic layer like the serverless framework?
Developers also need to make choices on the dark art of state management. FaaS functions only solve the compute part, but where is data stored and managed, and how is it accessed? This is important as each platform has different persistence models and APIs, tying you to that vendor’s ecosystem. What is more, as the world adopts the event-driven, streaming architecture, how does it fit with serverless? Do they complement or compete? When it comes to the emerging serverless world, It makes sense to validate how Apache Kafka® fits in considering that it is mission critical in 90 percent of companies.

Serverless functions provide a synergistic relationship with event streaming applications; they behave differently with respect to streaming workloads but are both event driven
In part 1 of this series, we developed an understanding of event-driven architectures and determined that the event-first approach allows us to model the domain in addition to building decoupled, scalable and enterprise-wide systems that can evolve.
The key to event-first systems design is understanding that a series of events captures behavior. By persisting the streams in Kafka we then have a record of all system activity (a source of truth), and also a mechanism to drive reactions. Normally these events a handled by stream processors or consumers; however, in this case we want to understand how FaaS functions fit into the event streaming model.
We will also explore how FaaS runtime characteristics make it suitable for different types of processing, as in some cases, latency or concurrency concerns need to be catered for. After working through the requirements of stream processing, I’ll then develop several principles showing that FaaS does indeed work with the model of event streams, despite some caveats.
Overview
- What is FaaS?
- Event-first FaaS?
- FaaS for streaming processing
- FaaS as part of the event-driven, streaming architecture
- Next Steps
To read the other articles in this series, see:
- Journey to Event Driven – Part 1: Why Event-First Thinking Changes Everything
- Journey to Event Driven – Part 2: Programming Models for the Event-Driven Architecture
- Journey to Event Driven – Part 4: Four Pillars of Event Streaming Microservices
What is FaaS?
The thing I like most about FaaS is the name and how everyone uses it as an attempt at humor. I will resist ;).
FaaS is the ability to take a function and run it somewhere in the cloud; it’s the “compute” part of the serverless stack where you bring your own code. The function contains a bespoke logic block. It is then called via some kind of registry like an API gateway, or it is scheduled or triggered by a cloud-related event (i.e., data written to Amazon S3).
The function is expected to run for a period of time and then exit, with cloud vendors charging by the millisecond (and associated memory). The functions can have many instances running in parallel, and after the first “cold” start call, they are considered “hot.” The first call is where database connections (and the like) should be initialized. When calling via an API gateway, functions might be called synchronously to return a value.
There are many benefits to FaaS:
- Lightweight
- Decoupled
- Scalable
- Very cost efficient (pay per use)
Many people predict that we will just be building cloud apps via the composition of FaaS functions. They moved from simple use cases like, “build a thumbnail of this image,” to mainstream application logic like process payments. The more recent developments around AWS Step Functions and Azure Durable Functions (patterns) reveal future direction.
You can read more about CloudEvents in part 1 of this blog series.
Event-first FaaS
Applying event-first principles to FaaS is relatively straightforward. From an infrastructure perspective, you need a streaming provider through which the events are stored and used to trigger FaaS functions. With Kafka, this would involve using a connector to bridge between a Kafka topic and the FaaS function. As each event is received, it calls on the specified FaaS function.
All of the above principles hold true from an architecture perspective as well. The event models a fact, the FaaS function reacts to that fact; it might generate an event of its own. The nice thing about this is that it moves away from the FaaS integration challenge. It is common to use FaaS to react to events from S3 or other parts of your cloud infrastructure. The challenge is the inherent scale and complexity as your application grows, coupled with the loss of ability to trace events and manage functionality. By routing all events through streams, they are stored as facts. These facts are consumed by the connector which is then used to trigger the appropriate FaaS function.
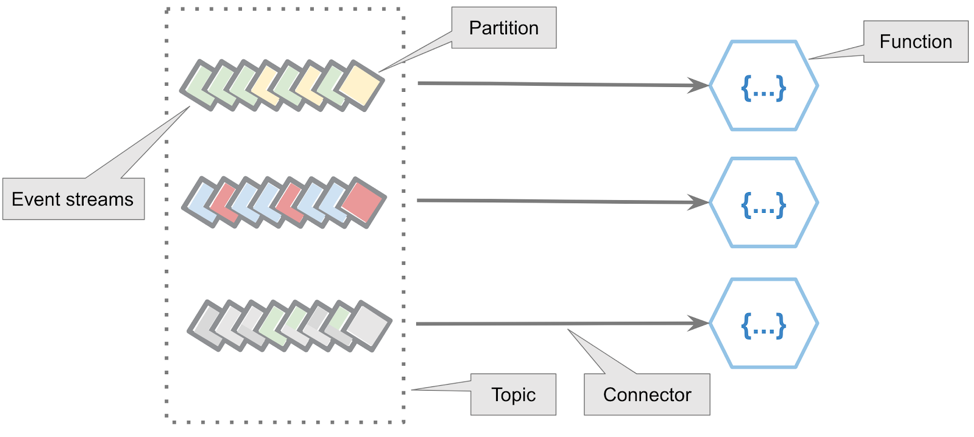
FaaS for stream processing
In our event-driven, streaming application, we have the behavior of our domain model being captured (persisted) as events within streams. Stream processors allow us to work natively with these streams in a “correct” fashion by supporting a myriad of patterns with either bespoke logic, such as Kafka Streams, or a higher-order grammar: ksqlDB. These are composed as an event stream that works quite well…which leads us to the question: When and where should FaaS be used? Can I use it to enrich user information from external sources or filter against a particular set of users?
To answer this accurately, we need to establish the characteristics that make FaaS well suited to different types of processing.
| Attribute | Native stream processing | FaaS processing |
| Eventing model | Async | Function limit (AWS 1,000 soft limit) |
| Latency | Low (<10 ms) | High (cold: 5 s), (hot: 25–300 ms) |
| Throughput | High | Medium high |
| Elasticity | Externally driven, per node | Native, (per function instance) |
| Stream correctness | Yes | No |
| Stateless operation (filter, enrich, transform) | Yes | Yes |
| Stateful operations (window, aggregate) | Yes | Bespoke (build it yourself) |
| Stream patterns (fan out, fan in/join) | Yes | Yes, but choose the use case appropriately |
| Cost | Consumption based with high residual (always needing a processor running) | Consumption based |
| Runtime | VM, container, server | FaaS provider |
| Runtime limits | Bespoke | Provider dependent: 500 MB storage, 128 MB → 3,008 MB memory |
As conveyed through the quote below, even after eliminating the common considerations of FaaS, there may still be adverse side effects and runtime characteristics due to implementation side effects, including function contention, resource governance, etc.
We characterize performance in terms of scalability, cold start latency, and resource efficiency, with highlights including that AWS Lambda adopts a bin-packing-like strategy to maximize VM memory utilization, that severe contention between functions can arise in AWS and Azure, and that Google had bugs that allow customers to use resources for free.
Mapping these together, we begin to see the overlap where FaaS affords a cost efficiency currently unavailable with stream processing.
- Low latency: Single event processing in FaaS is too slow for stream processing (for a warm start, AWS: 25 ms, Google: 79 ms and Azure: 320 ms). However, record batching into groups of events overcomes latency concerns. Note: Async payload limit = 128 KB. Sync payload limit = 6 MB. YES
- High throughput: By batching records together and utilizing parallelism, significant throughput can be achieved, i.e., five parallel functions processing 1,000 events every 200 ms provides a throughput of 5 x 1,000 per 200 ms = 25,000 events per second. YES
- Stateless operation: Filtering, transformation and enrichment (i.e., load from a static table) are possible. YES
- Stream-oriented stateful operations: Stream-stream/stream-table joins, windowing, etc., aren’t natively supported. NO
- Non-streaming stateful operations: Stream-external-table joins and stream enrichment from external sources are possible provided the external data is not in motion. YES
- Stream correctness (order preservation): There are no guarantees about invocation of container reuse, meaning correctness cannot be guaranteed beyond the scope of a single batch invocation. NO
- Stream patterns: Patterns are stateful—they are not possible. NO
Amazon’s recently published a white paper Serverless Streaming Architectures and Best Practices is a great read and makes some good points that should be mapped onto the constraints above.
AWS Lambda and serverless architectures are well-suited for stream processing workloads which are often event-driven and have spiky or variable compute requirements.
As shown in the recipes section of the paper, FaaS is great where events are treated atomically and are (mostly) stateless. They are processed in isolation to perform simple enrichment and filtering before passing to a storage layer or queue. If the system needs to guarantee event ordering when writing to an output stream then, as previously discussed, concurrent FaaS execution will lead to corruption unless they are synchronously driven at the partition level.
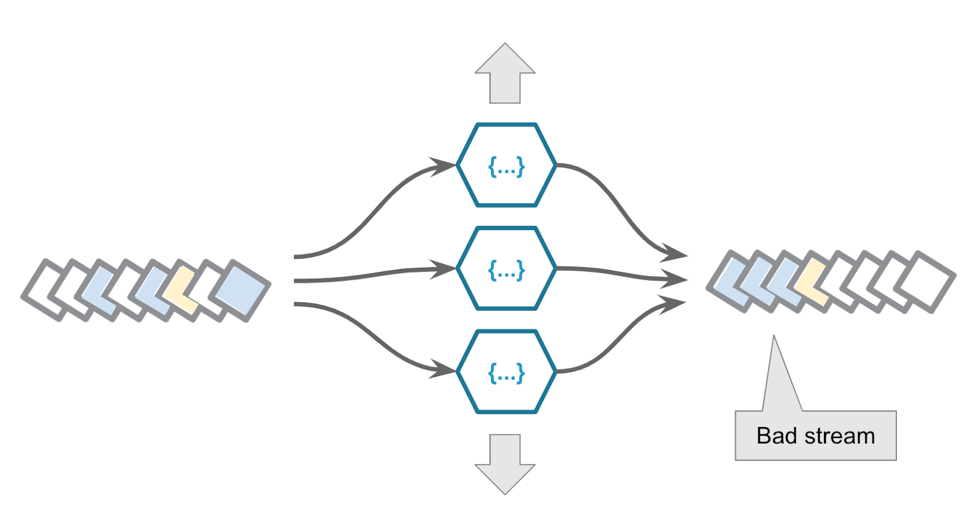
A source stream running through concurrent FaaS invocations will break event ordering.
For non-stream-oriented stateful processing, such as those that enrich against (static) external resources, then FaaS makes a lot of sense provided that the operation is not time sensitive. For example, stream-table join operations to enrich a user ID to username and address are easily supported where the event stream contains the user ID, and where DynamoDB contains a user table.
If the user information is updated then subsequent invocations against hot state could be incorrect. If stale data cannot be tolerated then the FaaS instance would need to check and reload for every event being processed.
The main problem with this approach (for non-static data) is that it is not event driven; you should never “fetch data.” Where time sensitivity is essential, the data should be provided as part of the event and processed using a stream processor that is time aware as part of its runtime (i.e., join events within a time window). Secondly, the cost of the “fetch” drives up the cost of the FaaS. You could pay to wait for an RPC which introduces latency; the alternative is to cached data locally, but then how would you know it was stale or how long to cache it for?
The final performance consideration is latency. FaaS is problematic with cold starts (three seconds for Java processes), and hot invocations are in the vicinity of 200 ms–300 ms. Resorting to batching overcomes some of the latency, but there is still an initial hit that results in erratic performance.
Caveat emptor: FaaS gives us an excellent solution where processing is atomic (stateless), reliable latency is not a concern (1–100 ms) and the order of processing is not important. Stateful processing is also suitable provided that it is against an external resource and stale data concerns are understood.
In the context of the streaming dataflow model, we can state the following.
FaaS event-driven principles:
- In band but edge (stateless on the way in or out), i.e., map user GeoIP to a geocell
- In band, stateless and not latency sensitive
- In band and enriched against external resources, i.e., enrich a user’s address
- Out of band, but edge: This is FaaS processing on a known set of data in response to an event where there is no downstream stream processing. For example, you can perform large-scale analytic processing of all auction site bidders against “cars in 2018” (a non-event-streaming problem).
- Ad hoc requests, but not streaming: They tend to be historic. If a large set of data is to be processed, then it is likely to be batch oriented. Historic analytics include Monte Carlo simulation, raw number crunching of event data, etc.
FaaS as part of the event-driven, streaming architecture
Fundamentally speaking, you can leverage AWS Lambda integration with Amazon Kinesis or the Kafka Connect AWS Lambda Sink Connector to trigger events from streams. So it depends on the orientation of your development methodology. Do you want to stick to the cloud vendor platform or adopt a vendor-agnostic approach? Many organizations favor the latter, which is the approach I will use.
In this example we are considering an auction platform:
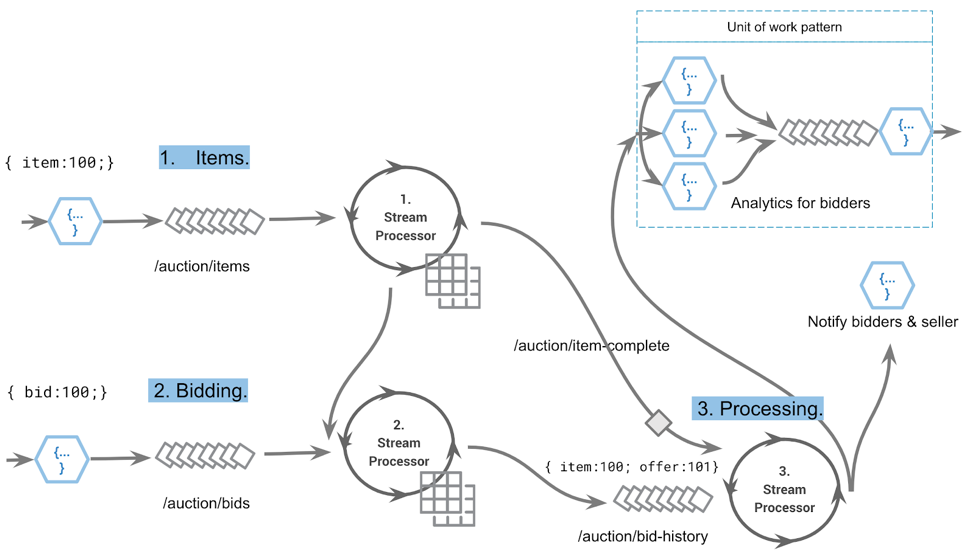
The event stream of an auction system: item placement, item bidding and processing
The above event stream shows FaaS functions on the edge processing part of our application. Real-time stateful operations are handled by stream processors; they interact with the log and with correctness guarantees due to the underlying streaming platform protocol. This model ensures temporal guarantees of stream-table joins, i.e., event time correctness.
Let’s step through the data flow above and focus on the FaaS functionality:
- When item events are sent to the system, they are received via a FaaS function. This function will validate, enrich and either reject the event, or write it into the /auction/items stream
- Similarly, bidding events enter the system via a FaaS function whose job is to validate, enrich and then store the event in the /auction/bids stream
- As events pass through the dataflow, an item-complete event is eventually emitted. This triggers a join reaction, and the output is a series of events to notify bidders and calculate analytics.
In the above example, FaaS functions 1 and 2 obey principle 1: inband but edge. The final stage of post-processing, notifying users, etc., also applies to principle 1.
If we wanted to include inband processing (principle 2), it might occur as shown below where step 3 (enrich) will process the item-complete event before passing it onto the item-validated topic. This is because the latency sensitivity does not affect system behavior. A user can wait 250 ms before receiving an email and associated bid analytics.
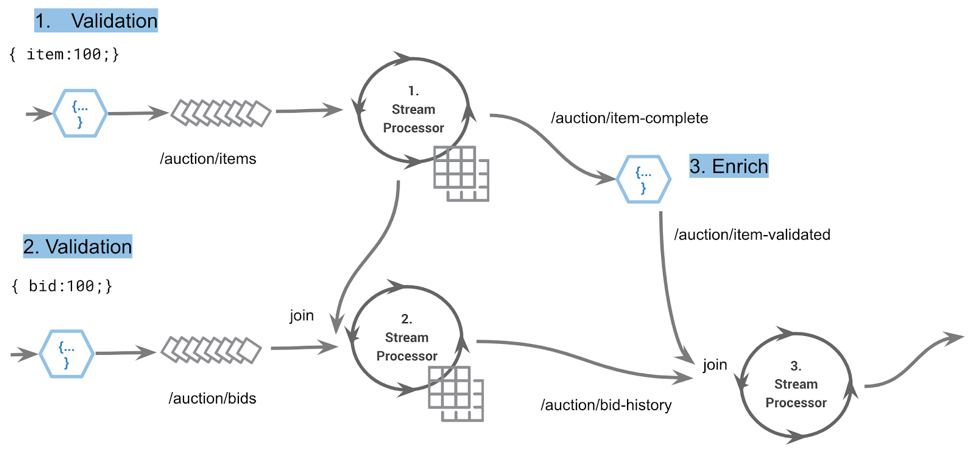
Provided the event streaming application obeys the FaaS streaming principles, then these functions can become part of any streaming application. As is generally the rule, an understanding of the use cases, awareness of side effects and touch of common sense means that it should be possible to build the systems of tomorrow that provide a rich collaboration between serverless runtimes and the event streaming platform.
Next steps
The synergy of FaaS and the event streaming platform is a natural fit when we think about domain modeling and organizational needs as they change over time. Whether it’s business processes, data models, technology, cloud or just the organization itself, evolution is inevitable and needs to be embraced. We aren’t quite there yet, but it’s undeniable that FaaS is moving at a fast pace, along with streaming and cloud.
In the context of building event-driven microservices with Kafka or event streaming apps; they are all names for the same thing. The core concept that enables the functionality is the “event” and the ability to record, replay and react to events. Building systems around this principle is fine for streams processors and clients that speak the event streaming platform protocol; however, FaaS doesn’t. As such, we need to ensure that we FaaS functions are operated in such a way so as not to compromise the stream of events but instead be used for the right type of data workloads. Hence, I developed the Faas principles above.
What is next for FaaS?
The CNCF Serverless Working Group (which Confluent participates in) is shaping how FaaS will look in the next couple of years. There is a grand plan that CloudEvents should be publishable, emit through multiple transports and clouds and be consumed by a destination function that is written in any language. Now let’s just pause for a moment and understand the gravity of this. The barrier to cloud becomes pushed down, language considerations are no longer required and propagation of a CloudEvent can potentially go anywhere within the realms of a sanctioned network security domain.
We have baked into our ideology that events are the future. Making this a reality will further push us to support them at a greater scale and complexity that works seamlessly with FaaS. The (current) clunky barriers that make FaaS feel like duct tape on driving functionality will be broken down to be part of the streaming story. The net effect will be observability, security and a raft of other beneficial considerations that we need to embrace to ensure we don’t fall into previous trappings.
After all, it shouldn’t be possible for something to get lost in an ocean of FaaS events or stream processors without understanding lineage and instrumentation—do they need to be event sourced? Many lessons have been learnt in the past; I believe we now know enough to stand on the shoulders of giants.
Stay tuned for part 4, where I’ll discuss the art of the event streaming application and cover streams, stream processors and scale.
To learn more about event-driven systems, design and concepts I highly recommend Martin Kleppmann’s Designing Data-Intensive Applications, Ben Stopford’s book Designing Event-Driven Systems and The Future of Serverless and Streaming podcast.
If you’d like to know more, you can download the Confluent Platform, the leading distribution of Apache Kafka.
Other articles in this series
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Getting Started with Generative AI
This series of blog posts will take you on a journey from absolute beginner (where I was a few months ago) to building a fully functioning, scalable application. Our example Gen AI application will use the Kappa Architecture as the architectural foundation.


GPT-4 + Streaming Data = Real-Time Generative AI
ChatGPT and data streaming can work together for any company. Learn a basic framework for using GPT-4 and streaming to build a real-world production application.