[Webinar] Harnessing the Power of Data Streaming Platforms | Register Now
Announcing the MongoDB Atlas Sink and Source Connectors in Confluent Cloud
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Today, Confluent is announcing the general availability (GA) of the fully managed MongoDB Atlas Source and MongoDB Atlas Sink Connectors within Confluent Cloud. Now, with just a few simple clicks, you can link the power of Apache Kafka® together with MongoDB to set your data in motion.
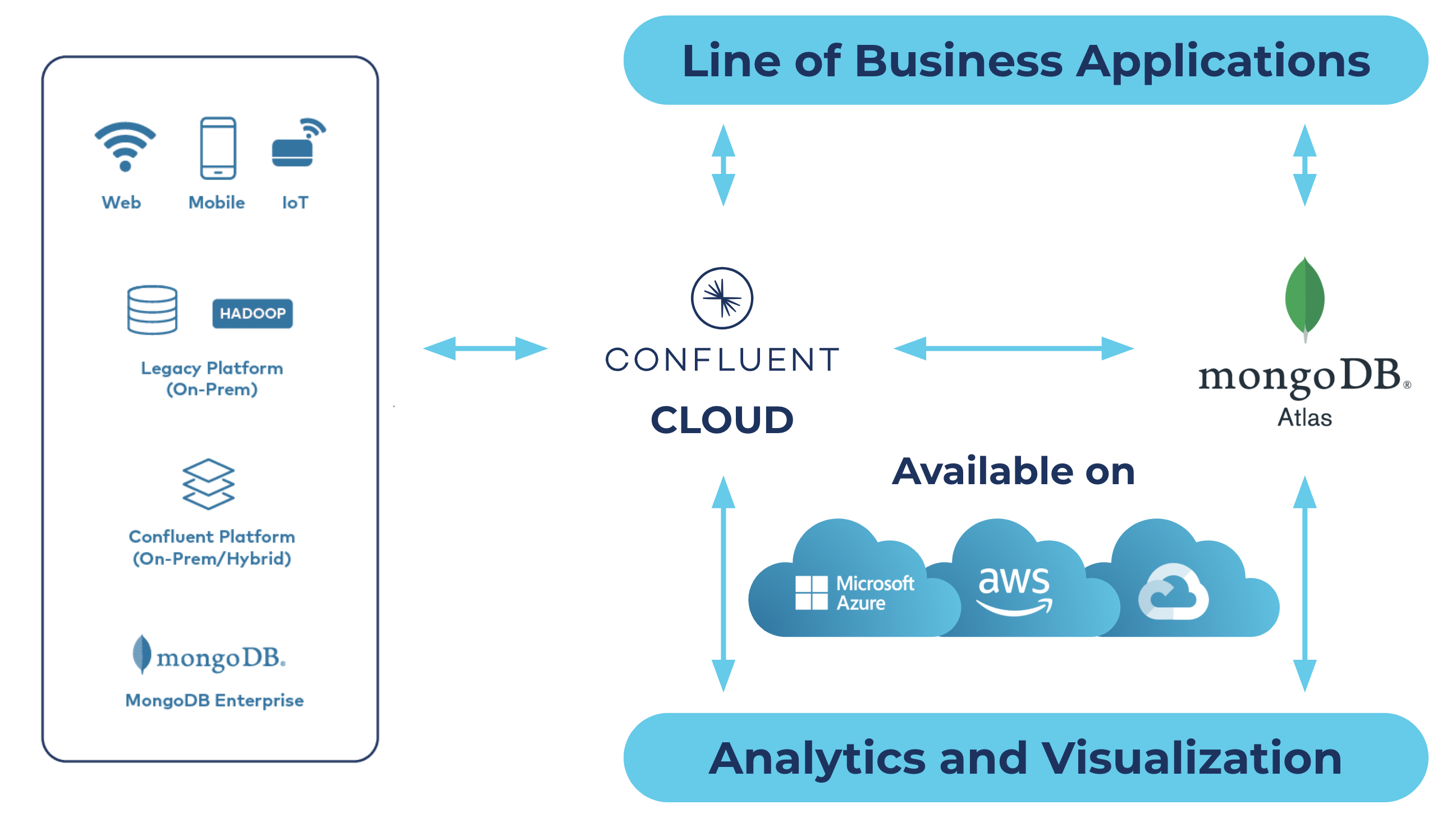
Confluent Cloud and MongoDB Atlas overview
Our new fully managed connectors eliminate the need for development and management of custom integrations and thereby reduce the overall operational burden of connecting your data between these two best-of-breed open source technologies, Kafka and MongoDB. Setup is available across all major cloud providers, including AWS, Microsoft Azure, and Google Cloud. According to Jeff Sposetti, VP of product management for analytics & tools at MongoDB,
“Kafka and MongoDB make up the heart of many modern data architectures today. We are excited to work with the Confluent team to make the MongoDB connectors available in Confluent Cloud. These managed connectors make it easy for users to connect Kafka with MongoDB Atlas when processing real-time event streaming data.”
Before we dive into the MongoDB Atlas Source and Sink Connectors, let’s recap what MongoDB Atlas is and does.
What is MongoDB Atlas and how does Confluent make it better?
MongoDB Atlas is a global cloud database service for modern applications, available as part of the MongoDB cloud platform. Atlas is a fully managed service that handles the complexity of deploying, managing, and scaling your deployments across AWS, Microsoft Azure, or Google Cloud. Atlas provides best-in-class compliance to meet the most demanding data security and privacy standards. When developing single-view databases, real-time IoT databases, content management & personalization repositories, or any other use case on MongoDB, leveraging Confluent’s fully managed connectors is the easiest means to preparing the data that brings these experiences to life, no matter where it comes from or where it needs to land.
Getting started with Confluent Cloud and MongoDB Atlas
To get started, you’ll need a Kafka cluster setup in Confluent as well as a MongoDB Atlas database. The easiest and fastest way to spin up a MongoDB database is to use MongoDB Atlas. No more fumbling around with provisioning servers, writing config files, and deploying replica sets—simply pick a cloud provider, a cluster size, and get a connection string!
Once you have your MongoDB Atlas database, you’ll need to configure it to allow network access from Confluent.
By default, MongoDB Atlas does not allow any external network connections, such as those from the internet. To allow external connections, you can add a specific IP or a CIDR IP range using the “Add IP Address” entry dialog under the “Network Access” menu. In order for Confluent to connect to Atlas, you need to specify the public IP address of your Confluent cluster. If you have a Kafka cluster running on AWS with the “Public Internet” option, you will be able to use static egress IPs. Once the static egress IPs are enabled for your organization, you will be able to see a list of 10 IP addresses under the “Networking” tab of the cluster setting. For other networking options and cloud providers, please review the documentation.
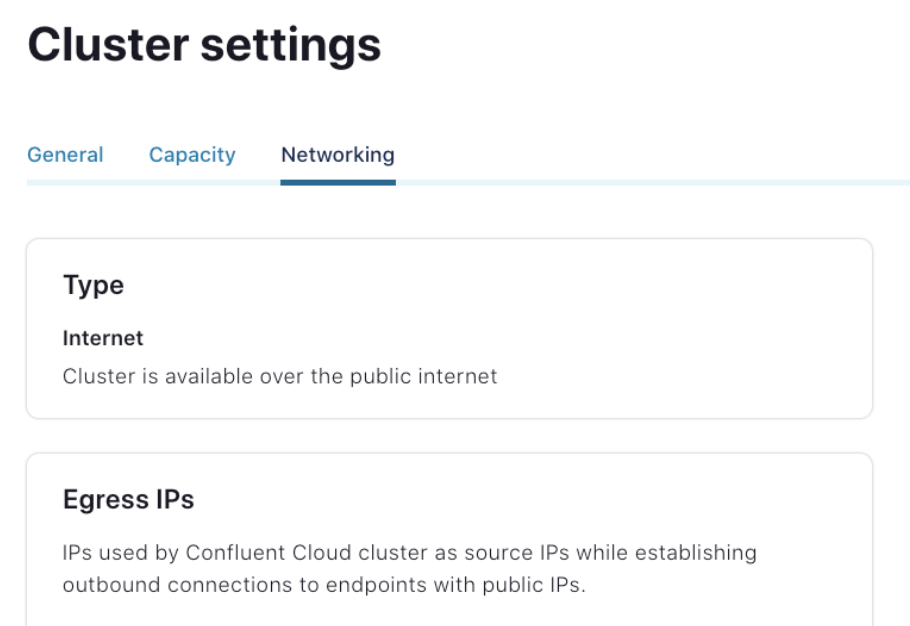
Confluent Cloud
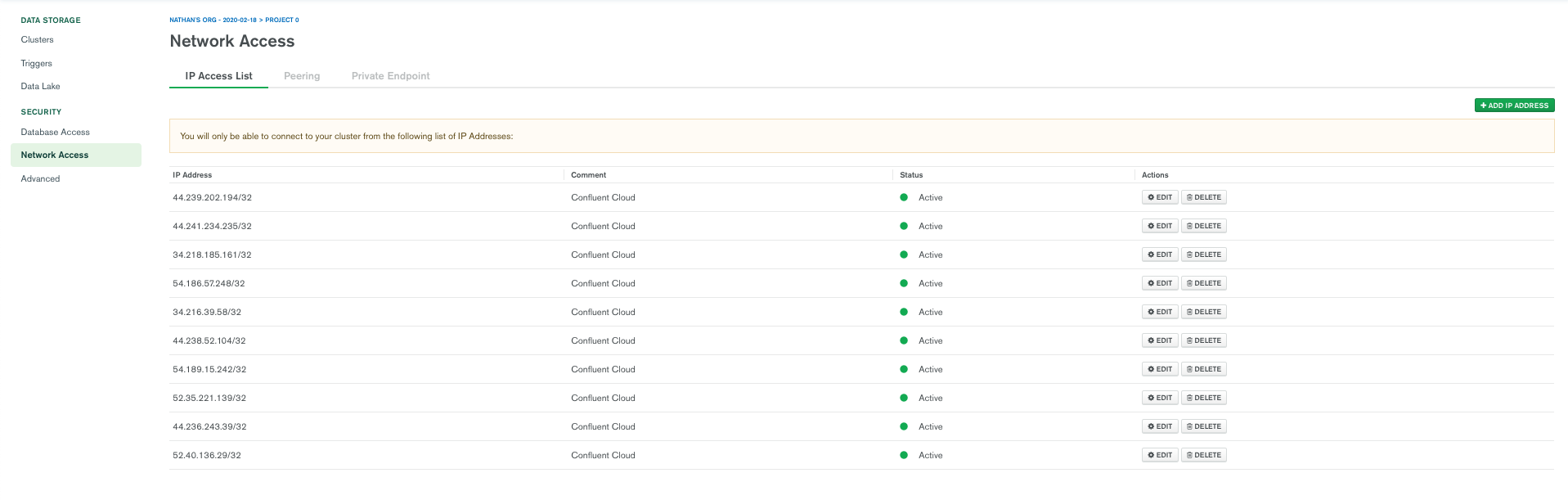
Mongo Atlas
With network access in place, we’ll now walk through how to configure the MongoDB Atlas Source and Sink Connectors followed by a use case example for each.
- First, we will show MongoDB used as a source to Kafka, where data flows from a MongoDB Atlas collection to a Kafka topic
- Next, we will show MongoDB Atlas used as a sink, where data flows from a Kafka topic to MongoDB
Note: When using the MongoDB Atlas Source Connector, Confluent can fetch records from MongoDB Atlas regardless of your cloud provider or region. However, when using the MongoDB Atlas Sink Connector, your Atlas database must be located in the same region as the cloud provider for your Kafka cluster in Confluent. This prevents you from incurring data movement charges between cloud regions. In this blog post, the MongoDB Atlas database is running on GCP us-central1 and the Kafka cluster in Confluent Cloud is running in the same region.
Using the fully managed MongoDB Atlas Source Connector
Consider the use case of launching a food delivery service in a new region with the restaurant data stored in MongoDB Atlas. We plan to target restaurants that have a high rating first. To test out our scenario, we will use the sample restaurants dataset that MongoDB provides, and we can simply load this dataset to a MongoDB Atlas database.
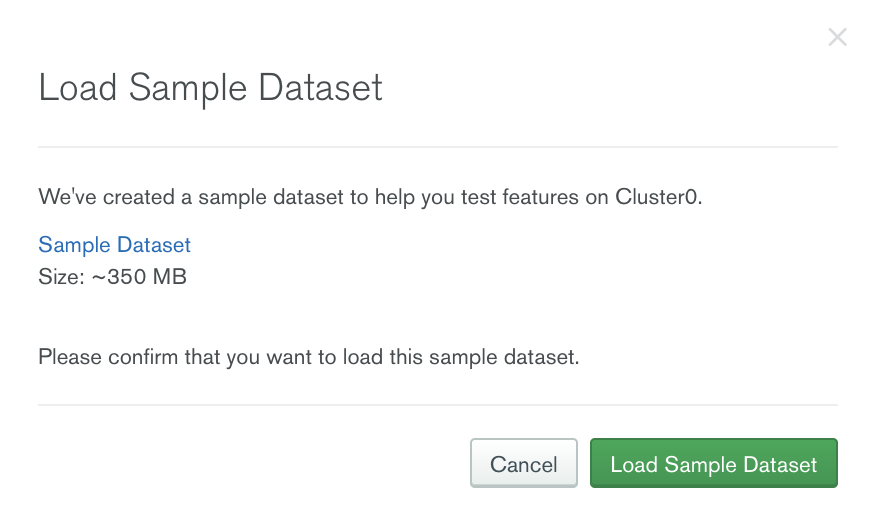
Once the sample dataset is loaded, we will be able to see a collection called restaurants.
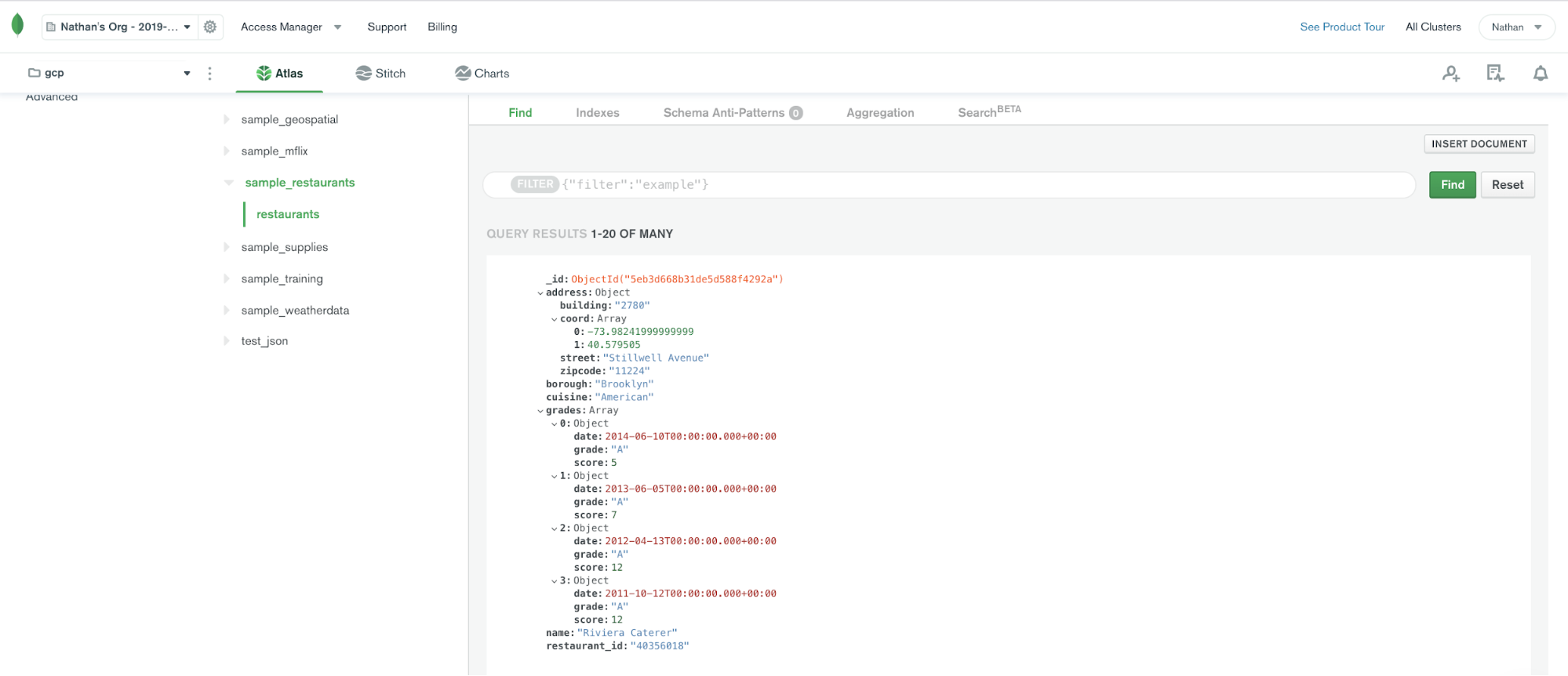
Click the MongoDB Atlas Source Connector icon under the “Connectors” menu and fill out the configuration properties with your MongoDB Atlas details. Note that the connector exposes a subset of the options available on the self-hosted MongoDB Connector for Apache Kafka. Over time, more options, such as being able to specify an aggregation pipeline parameter, will be exposed. Check out the MongoDB Atlas Connector documentation for the latest information on supported connector properties.
There are a number of exciting features worth highlighting in the GA release. You can select various output formats, including AVRO, JSON_SR, and PROTOBUF, enabling a connector to imply a schema based on records from MongoDB and to properly register it in the Confluent Cloud Schema Registry. Having a schema will greatly simplify transformations handled by ksqlDB or downstream applications.
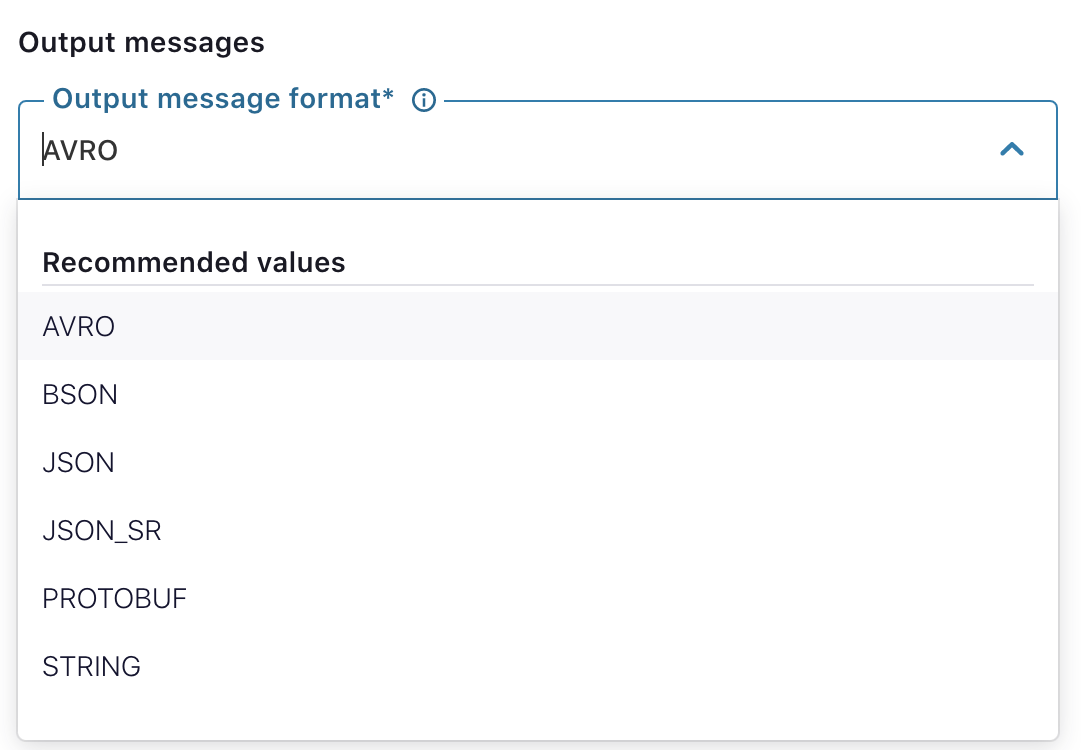
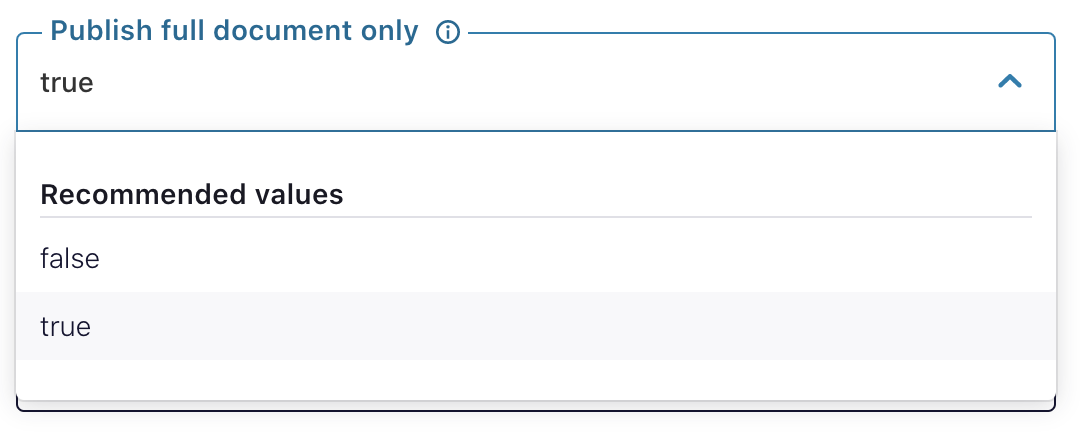
By default, the MongoDB Atlas Source Connector fetches records with various metadata. Many users only require the record itself. When Publish full document only is set true, the connector will only write the record from MongoDB Atlas.
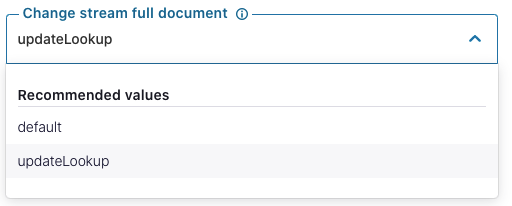
Last but not least, when a subset of a record is changed, you now have the option to fetch just that change or the entire updated record. The former will occur by default. By simply setting “Change stream full document” to updateLookup, the connector will fetch the whole record.
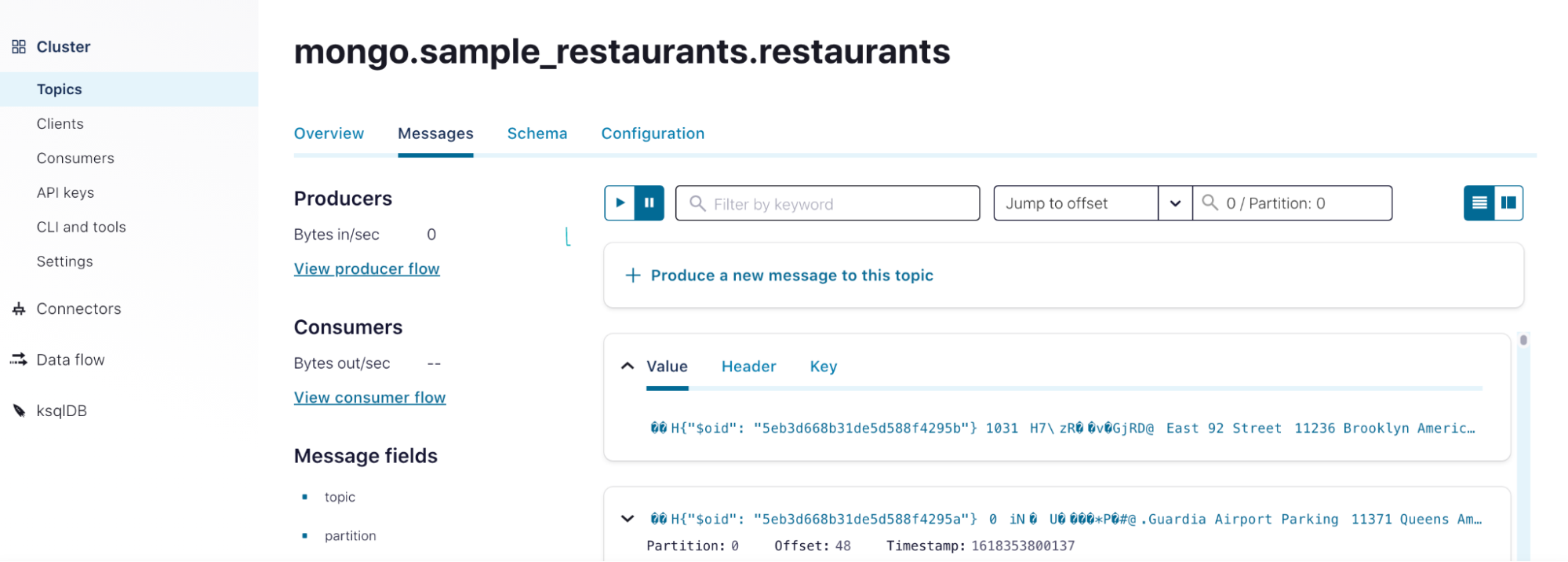
Once the connector is up and running, use a message browser to see restaurant records. By putting 0 / Partition: 0, records similar to the image below will show up for the mongo.sample_restaurants.restaurants topic. With restaurant records in a Kafka topic, you can leverage ksqlDB to calculate the average rating for each restaurant and to focus on ones above a certain threshold.
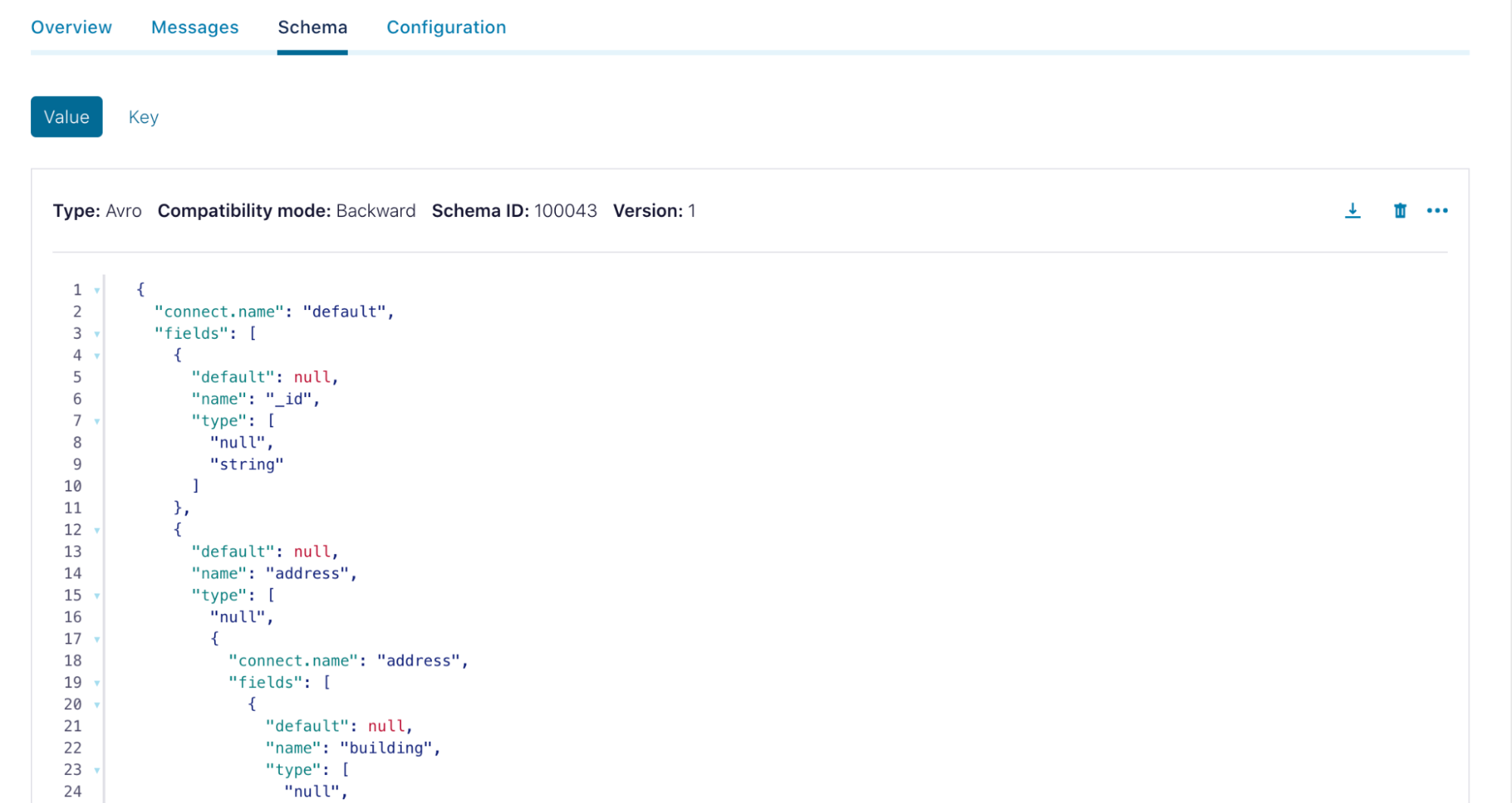
If you click on the Schema tab, you will be able to see the schemas auto-generated by the MongoDB Atlas Source Connector.
With restaurant records in a Kafka topic, you can leverage ksqlDB to calculate the average rating for each restaurant and focus on ones above a certain threshold.
Using the fully managed MongoDB Atlas Sink Connector
Continuing the food delivery scenario, when a new user is created on the website, multiple business systems want their contact information. Contact information is placed in the Kafka topic users for shared use, and you can then configure MongoDB as a sink to the Kafka topic. This allows a new user’s information to propagate to a users collection in MongoDB Atlas.
To accomplish this, first create the topic users for a Kafka cluster running in Confluent (Google Cloud us-central1).
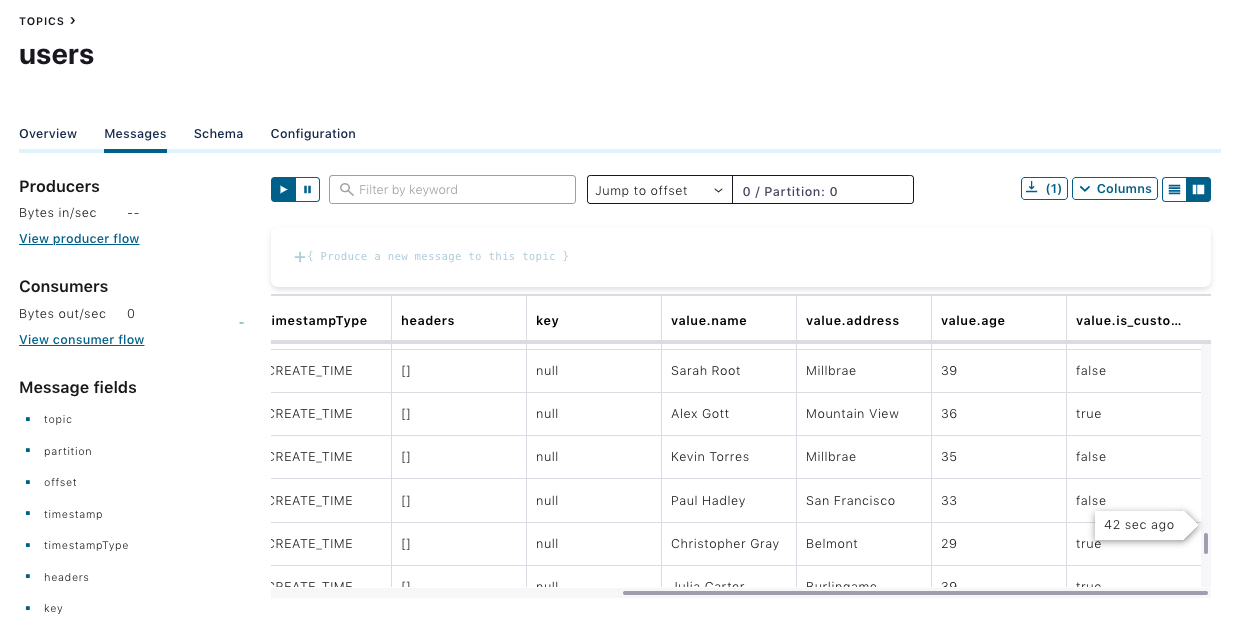
Use this Python script to populate sample records to the users topic, and check whether the records are available in the users topic.
Click the MongoDB Atlas Sink Connector icon under the “Connectors” menu, and fill out the configuration properties with your MongoDB Atlas details. Make sure “JSON” is selected as the input message format, and leave the collection name field bank. The connector will use the users topic as a collection name.
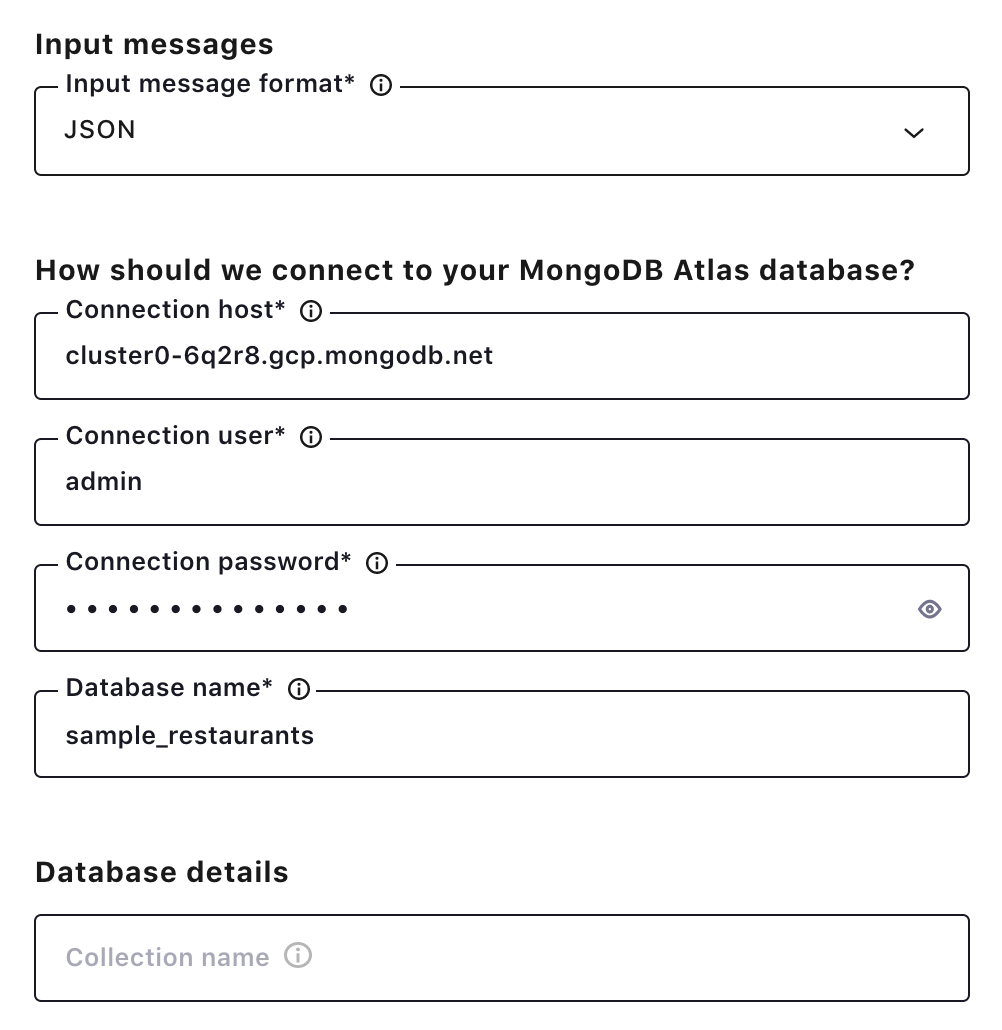
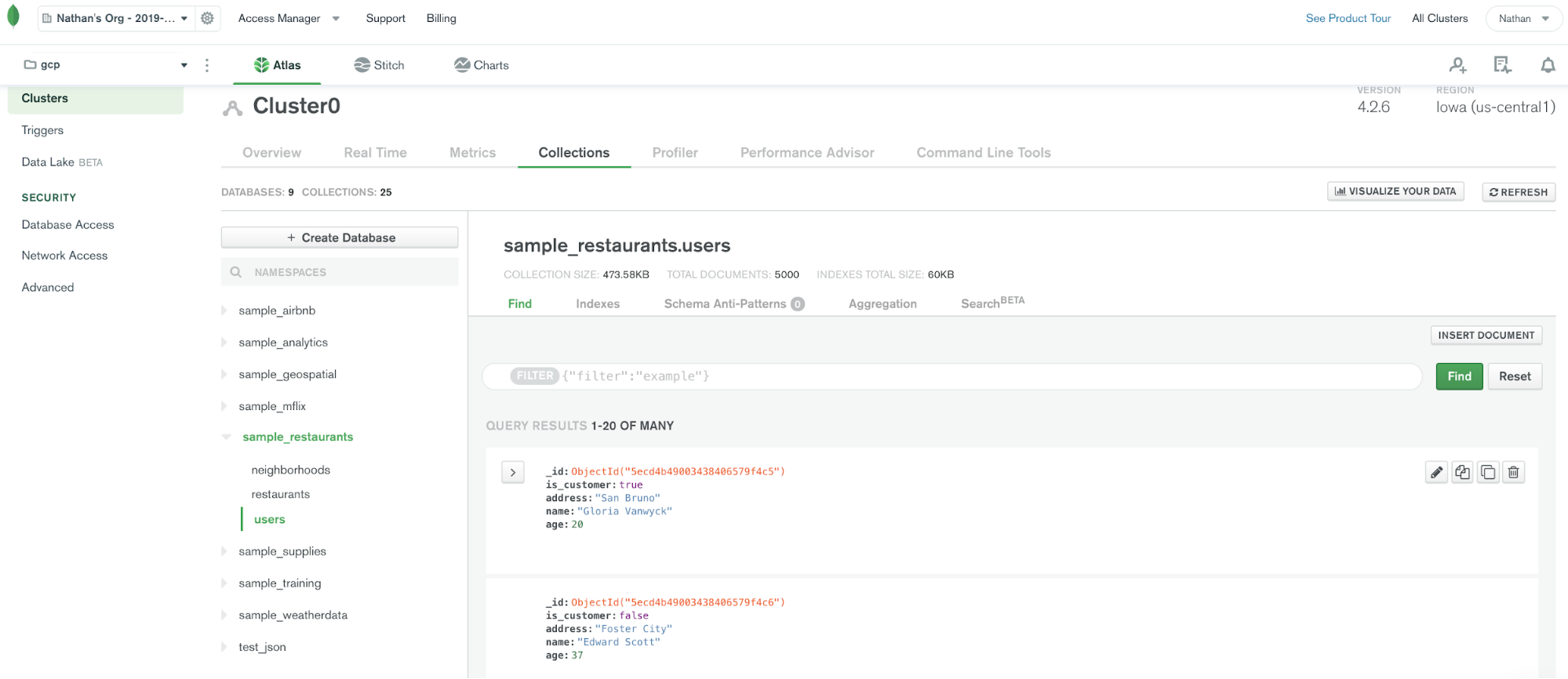
Once the connector is up and running, records for the user collections will show up in the MongoDB Atlas database.
Learn more about the MongoDB Atlas Sink and Source Connectors
To learn more about these fully managed connectors, join us for a joint online talk with MongoDB.
If you haven’t yet, sign up for a free trial of Confluent Cloud in order to start using the MongoDB Atlas Source and Sink Connectors or any other fully managed connector. You can use the promo code CL60BLOG for an additional $60 of free usage.*
Want to keep learning more about MongoDB and Confluent? Check out the Confluent and MongoDB Reference Architecture, as well as the MongoDB announcement blog post: How to Get Started with MongoDB Atlas and Confluent Cloud.
Further reading
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...