Introducing Connector Private Networking: Join The Upcoming Webinar!
How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Scalable Machine Learning in Production with Apache Kafka®
Intelligent real time applications are a game changer in any industry. Machine learning and its sub-topic, deep learning, are gaining momentum because machine learning allows computers to find hidden insights without being explicitly programmed where to look. This capability is needed for analyzing unstructured data, image recognition, speech recognition, and intelligent decision making. It is an important difference from traditional programming with Java, .NET, or Python.
While the concepts behind machine learning are not new, the availability of big data sets and processing power allow every enterprise to build powerful analytic models. Plenty of use cases exist in any industry to increase revenue, reduce cost or improve customer experience by applying analytic models in enterprise applications and microservices.
This post discusses potential use cases for machine learning in mission-critical real time applications leveraging Apache Kafka® as central, scalable, mission-critical nervous system plus Apache Kafka’s Streams API to build intelligent streaming applications.
Scalable, Mission-Critical Real Time Applications
The emergence of the Internet, smartphones, and always-on thinking has changed how people behave today. This includes people’s expectations about how devices, products, and services interact with them: people expect information in real time now. The challenge for enterprises is to act on critical business moments before it is too late. Batch processing is not sufficient anymore. You need to act immediately, or even better: proactively.
Traditional enterprises can implement very powerful real time processing for their daily business. Often, domain knowledge is needed to understand the scenario and build new streaming analytics to add business value. Stream Processing use cases exist in every industry, for example:
- Fraud detection: Correlate payment information with other historical data or known patterns to detect fraud before it happens. This typically needs very fast processing as you must decline a transaction before settling the stock movement, sharing the information or shipping the item.
- Cross-selling: Correlate customer big data to make context-specific, personal, customized offers or discounts before the customer leaves the store. You leverage real time information (like location-based data, payment data), but also historical data (like information from your CRM or Loyalty platform) to make the best offer to every single customer.
- Predictive maintenance: Correlate machine big data to predict failure before it happens. This allows replacing parts before they break. Depending on the industry and use case, this can save a lot of money (e.g., manufacturing), increase revenue (e.g., vending machines) or increase customer experience (e.g., telco network failure prediction).
The key in all these use cases is that you process big data while it is in motion. You need to handle the event before it is too late to act. Be proactive, not reactive! Your system should make decisions before a fraudulent transaction happens, before the customer leaves the store, before a machine breaks.
This does not always mean that you need millisecond response time, though. Even batch processing of events is fine in several use cases. For example, in most manufacturing or Internet of Things (IoT) use cases for predictive maintenance, you monitor time windows of several hours or even days to detect issues in infrastructure or devices. Replacement of defective parts is sufficient within a day or week. This is a huge business case and saves a lot of money, because you can detect issues and fix them before they happen or even also destroy other parts in the environment.
Intelligent Real Time Applications Leveraging Machine Learning
Mission-critical real time applications like the above have been built for years—without machine learning. Why is machine learning the game changer?
If you read about machine learning and its sub-topic, deep learning, you often see examples like these:
- Image recognition. Upload a picture to your Facebook timeline, and objects like your friends, the background, or the beer in your hand are analyzed.
- Speech translation. This enables chat bots that communicate with humans via generated text or speech.
- Human-like behavior. IBM Watson has beaten the best Jeopardy players; Google’s AlphaGo has beaten professional Go players.
These examples become more and more relevant for enterprises looking to build innovative new applications and differentiate from competitors. In the same way, you can apply machine learning to more “traditional scenarios” like fraud detection, cross selling, or predictive maintenance to enhance your existing business processes and make better data-driven decisions. The existing business process can stay as it is. You merely replace the simpler custom coded business logic and rules by analytic models to improve the automated decision.
The following sections show how to build, operate and monitor analytic models in a scalable, mission-critical way by leveraging Apache Kafka® as a streaming platform.
Machine Learning – The Development Lifecycle to Deploy Analytic Models
Let’s first think about the development lifecycle of analytic models:
- Build: Use Machine Learning algorithms like GLM, Naive Bayes, Random Forest, Gradient Boosting, Neural Networks or others to analyze historical data to find insights. This step includes tasks like collection, preparation or transformation of data.
- Validate: Use techniques such as cross validation to double-check that the built analytic model works on new input data.
- Operate: Deploy the built analytic model to a production environment to apply it on new incoming events in real time.
- Monitor: Watch the outcomes of the applied model. This contains two parts: Send alerts if a threshold is reached (business monitoring). Assure that the accuracy and other metrics are good enough (analytic model monitoring).
- Continuous Loop: Improve the analytic model by going through all above steps continuously. This can be done in manual batch mode (say, once a week) or online, where the model is updated for every incoming event.
The whole project team must work together from the beginning to discuss questions like:
- How does it need to perform in production?
- What technology does the production system use or support?
- How will we monitor the model inference and performance?
- Do we build a complete machine learning infrastructure covering the whole lifecycle or using existing frameworks to separate model training from model inference?
For example, a data scientist can build a Python program, which creates a model that scores very well with high accuracy. But this does not help as you cannot deploy it to production because it does not scale or perform as needed.
I suspect you can already imagine why Apache Kafka® is a perfect fit for productionizing analytic models. The following section will explain the usage of Apache Kafka® as a streaming platform in conjunction with machine learning/deep learning frameworks (think Apache Spark) to build, operate, and monitor analytic models.
Reference Architecture for Machine Learning with Apache Kafka®
After you understand the Machine Learning Development Lifecycle, let’s look at a reference architecture for building, operating and monitoring analytic models with Kafka:
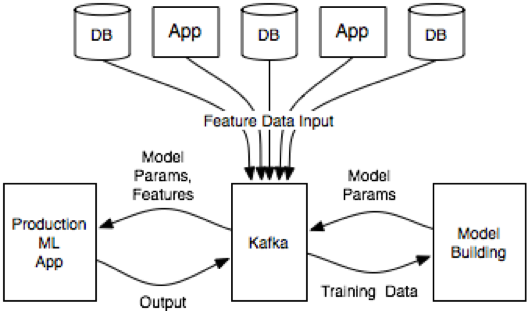
The essence of this architecture is that it uses Kafka as an intermediary between the various data sources from which feature data is collected, the model building environment where the model is fit, and the production application that serves predictions.
Feature data is pulled into Kafka from the various apps and databases that host it. This data is used to build models. The environment for this will vary based on the skills and preferred toolset of the team. The model building could be a data warehouse, a big data environment like Apache Spark or Hadoop, or a simple server running python scripts. The model can be published where the production app that gets the same model parameters can apply it to incoming examples (perhaps using Kafka Streams to help index the feature data for easy usage on demand). The production app can either receive data from Kafka as a pipeline or even be a Kafka Streams application itself.
Kafka becomes the central nervous system in the ML architecture to feed, build, apply and monitor analytic models. This establishes huge benefits:
- Data pipelines are simplified
- Building analytic modules is decoupled from servicing them
- Usage of real time or batch as needed
- Analytic models can be deployed in a performant, scalable and mission-critical environment
In addition to leveraging Kafka as a scalable, distributed messaging broker, you can also add optional components of the Kafka ecosystem like Kafka Connect, Kafka Streams, Confluent REST Proxy, Confluent Schema Registry or KSQL instead of relying on the Kafka Producer and Consumer APIs:
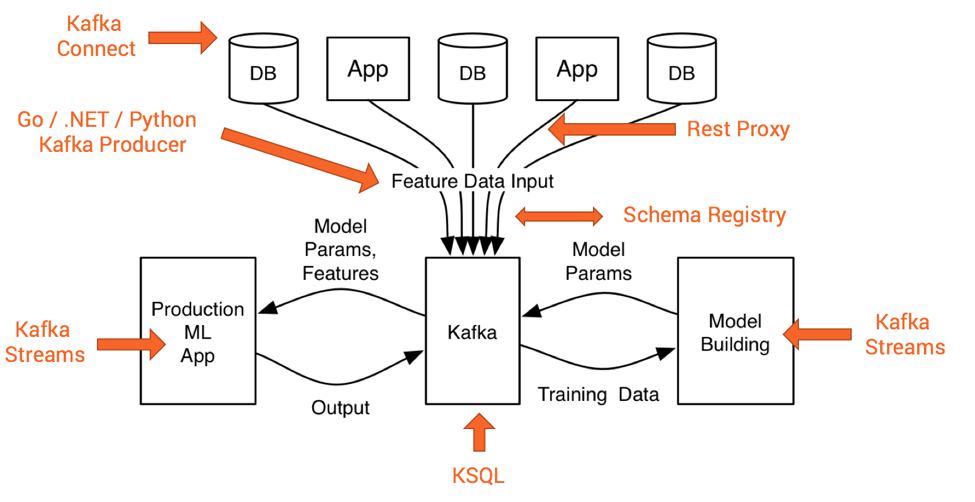
The next two sections explain how to leverage Kafka’s Streams API to easily deploy analytic models to production.
Example for Machine Learning Development Lifecycle
Let’s now dive into a more specific example of an ML architecture designed around Kafka:
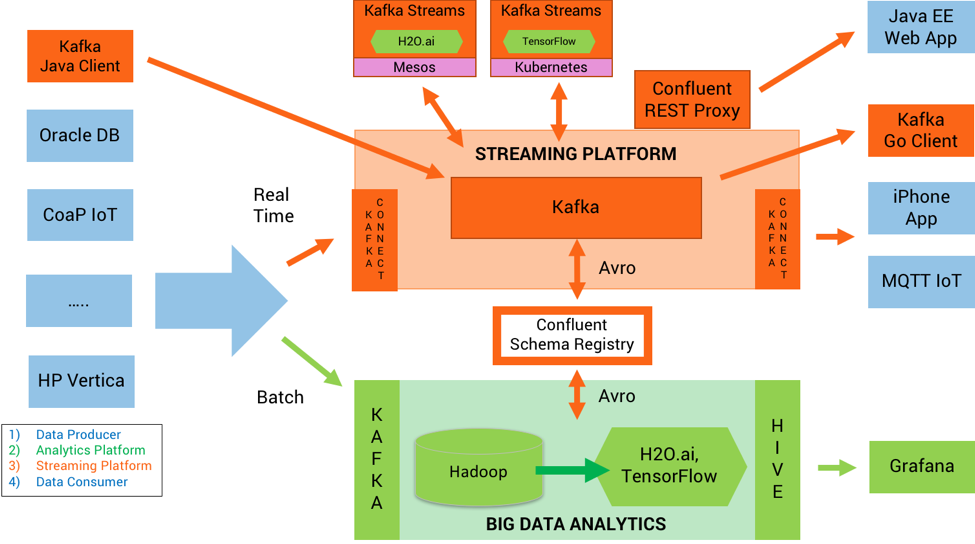
In green, you see the components to build and validate an analytic model. In orange, you see the streaming platform where the analytic model is deployed, infers to new events, and monitoring.
Data producers send messages continuously. The analytics platform receives this data either in batch or real time. It uses machine learning algorithms to build analytic models. The analytic models are deployed to the streaming platform. The streaming platform applies the analytic models to new events to infer a result (i.e. do a prediction). The outcome is sent to a data consumer.
In this example, we separate model training from model inference, which is the typical setup I have seen in most of today’s machine learning projects:
Model Training
Big data is ingested into a Hadoop cluster via Kafka. H2O.ai is used to analyze the historical data in Hadoop to build a neural network. The data scientist can use its preferred interface—R, Python, Scala, Web UI Notebook, etc.—for this. The model building and validation runs on the Hadoop cluster processing the data at rest. The result is a trained analytic model generated as Java code by H2O.ai. This is ready for production deployment.
Model Inference
The neural network is then deployed to a Kafka Streams application. The Kafka Streams application can run anywhere, whether it’s a standalone Java process, a Docker container, or a Kubernetes cluster. Here, it is applied to every new event in real time to do a prediction. Kafka Streams leverages the Kafka cluster to provide scalable, mission critical operations of analytic models and performant model inference.
Online Model Training
Instead of separating model training and model inference, we can also build a complete infrastructure for online model training. Many tech giants like Linkedin did this in the past leveraging Apache Kafka® for model input, training, inference and output. This alternative has several trade-offs. Most traditional companies use the first approach, which is appropriate for most use cases today.
Model Monitoring and Alerting
Deployment of an analytic model to production is just the first step. Monitoring the model for accuracy, scores, SLAs, and other metrics, and providing automated alerting in real time, is just as important. The metrics are fed back to the machine learning tool through Kafka to improve or replace the model.
Development of an Analytic Model with H2O.ai
The following shows an example of building an analytic model with H2O: An open source machine learning framework which leverages other frameworks like Apache Spark or TensorFlow under the hood. The data scientist can use his or her favorite programming language like R, Python or Scala. The great benefit is the output of the H2O engine: Java code. The generated code typically performs very well and can be scaled easily using Kafka Streams.
Here are some screenshots of H2O.ai Flow (web UI / notebook) and alternative R code to build an analytic model:
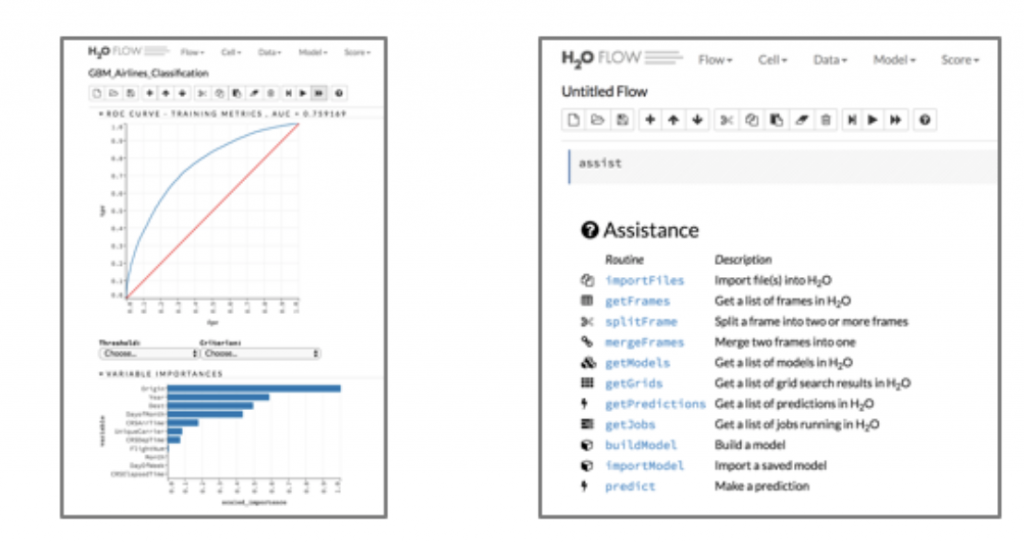
Building an Analytic Model with H2O Flow Web UI

Building an Analytic Model with H2O’s R Library
The output is an analytic model, generated as Java code. This can be used without re-development in mission-critical production environments. Therefore, you do not have to think about how to “migrate” a Python or R model to a production system based on the Java platform.
While this example uses H2O’s capabilities to generate Java code, you can do similar things with other frameworks like TensorFlow, Apache MXNet, or DeepLearning4J.
Deployment of an Analytic Model with Apache Kafka’s Streams API
Deployment of the analytic model is easy with Kafka Streams. Simply add the model to your stream processing application—which, recall, is just a Java application—to apply it on new incoming events:
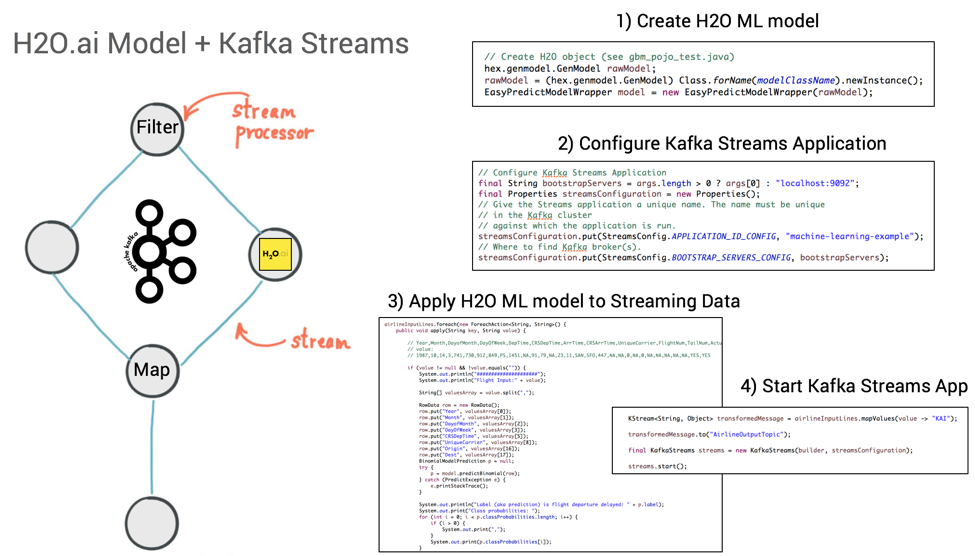
Apache Kafka’s Streams API to embed H2O.ai model into Kafka Streams
Since the Kafka Streams application leverages all Kafka features under the hood, this new application is ready for scale and mission-critical usage. There is no additional need to tweak the model because of production considerations.
You can find the running example on GitHub: https://github.com/kaiwaehner/kafka-streams-machine-learning-examples. Simply clone the project, run the Maven build, and see how the H2O model is used in the Kafka Streams application. This example will continue to evolve, with more sophisticated examples and use cases leveraging H2O and other machine learning frameworks like TensorFlow or DeepLearning4J in the roadmap for later.
Such an implementation of applying machine learning to stream processing can easily be integrated into any automated continuous integration workflow using your favorite tool stack for CI/CD environments, such as Maven, Gradle, Chef, Puppet, or Jenkins.
Sharing of an Analytic Model between Training and Inference using Open Standards
As discussed earlier already, you need to use an appropriate technology for building your analytic model. Otherwise you will not be able to deploy it into production in a mission-critical, performant, and scalable way. Some alternatives to share and update models between data scientists to develop and improve the model and DevOps teams to embed and productize the model:
- Native Model: Directly deploy a model to the stream processing engine, like deploying a Python model via JNI in a Java application
- Generated Code: Independent of the language used to build the model, a generated binary or source code can be deployed to the stream processing engine, which is optimized for performance. For example, the model is generated Java bytecode, even though the data scientist used R or Python to train it.
- External Server: Call to an external analytics server via request-response using analytics tools like SAS, MATLAB, KNIME, or H2O. This is typically done via a REST interface.
- PMML (Predictive Model Markup Language): An older XML standard with several limitations and drawbacks, but supported in some analytics tools.
- PFA (Portable Format for Analytics): A modern standard, including preprocessing in addition to the model. PFA leverages JSON and Apache Avro, and supports Hadrian. It is not yet supported out-of-the-box in most analytics tools.
There are various trade-offs between these alternatives. For instance, using a standard like PFA creates additional efforts and restrictions but adds independence and portability. From Kafka perspective, where you typically have mission-critical deployments with high volume, the preferred option today is often generated Java code, which is performant, scales well, and can easily embedded into a Kafka Streams application. It also avoids communication with an external REST server for model inference.
Conclusion: Using a Streaming Platform to Deploy Analytic Models into Mission-Critical Deployments
Machine Learning can create value in any industry. Also, Apache Kafka® is rapidly becoming the central nervous system in many enterprises. Machine Learning is a fantastic use case for it! You can leverage Kafka for:
- Inference of the analytic model in real time
- Monitoring and alerting
- Online training of models
- Ingestion into the batch layer/analytics cluster to train analytic models there
You have seen some code examples in this blog post how to leverage Apache Kafka® and its Streams API to build a scalable, performant, mission-critical infrastructure for applying and monitoring analytic models. A live demo of this example can be found on Confluent’s YouTube channel.
As a follow-up to this blog post, we will present a demonstration of how to realize “Online Model Training” with Apache Kafka, Kafka’s Streams API, and Apache Mahout to build and deploy an Online Logistic Regression Algorithm. Here, we will both train and apply our machine learning models in real-time. Stay tuned!
About Apache Kafka’s Streams API
If you have enjoyed this article, continue with the following resources to learn more about Apache Kafka’s Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices.
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.